


Welcome to the World of Vision Language Models (VLMs)
Vision Language Models (VLMs) are taking the AI world by storm with their ability to understand and generate responses based on both visual and textual input. In this article, we explore the latest advancements in VLMs, focusing on the groundbreaking model, Idefics3.
Building the Future with Idefics3
If you’re looking to dive deep into the world of VLMs and understand how Idefics3 is shaping the future, you’re in the right place. This tutorial will walk you through the key components, functionalities, and performance metrics of this cutting-edge model.

The Power of Connectivity
One of the key aspects of Idefics3 lies in its ability to connect visual and textual information seamlessly. By leveraging a pixel shuffle strategy and incorporating newline characters to preserve 2D image structure, Idefics3 reduces the number of visual tokens while maintaining context and detail.
Training Insights
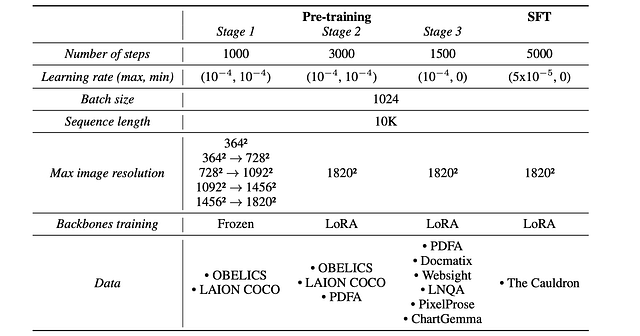
Training Idefics3 involves multiple stages, from freezing backbones to fine-tuning with DoRA and supervised training. With a strategic focus on increasing the image resolution and utilizing high-quality synthetic datasets, Idefics3 achieves superior performance across various benchmarks.
Performance and Future Directions
Idefics3 showcases significant improvements, particularly in document understanding tasks, and sets the stage for further advancements in VLM technologies. However, the need for larger models like Idefics2–70B highlights the importance of scale in capturing complex knowledge.
Ready to delve into the world of VLMs and stay ahead of the curve? Check out the full research paper here.
Keep exploring new horizons in the realm of Multi-Modal Transformers for more exciting developments!