


Time series forecasting is a crucial aspect of various industries, providing valuable insights for informed decision-making based on the prediction of future values of time-dependent data. Whether it’s forecasting daily sales revenue, hourly temperature readings, or weekly stock market prices, the ability to anticipate trends and future demands is key in areas such as product demand, financial markets, and energy consumption.
However, accurate forecasting can be challenging due to factors like seasonality, underlying trends, and external influences that can impact the data significantly. Traditional forecasting models often require domain expertise and manual tuning, making the process time-consuming and complex.
In this blog post, we delve into a comprehensive approach to time series forecasting using the Amazon SageMaker AutoMLV2 Software Development Kit (SDK). The AutoMLV2 tool automates the end-to-end machine learning workflow from data preparation to model deployment, making it easier for users to forecast future data points without extensive knowledge in model development. Throughout this post, we will explore data preparation, model configuration, inference, and key project aspects using AutoML to enhance time series forecasting capabilities.
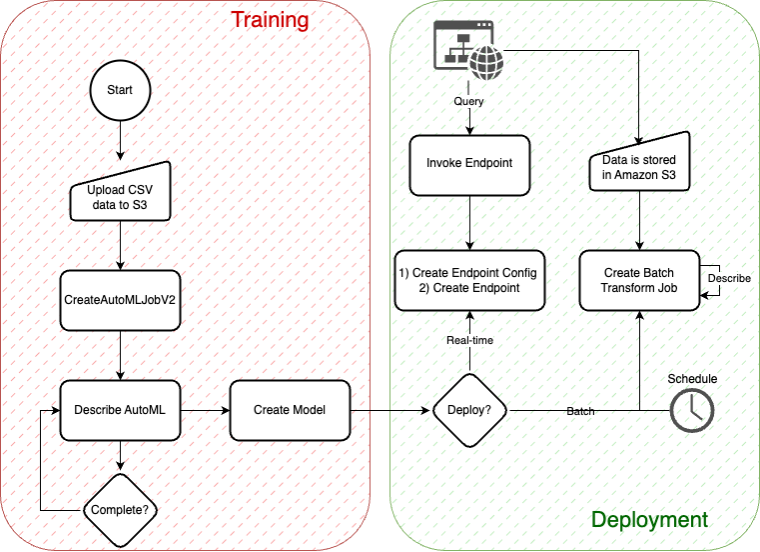
1. Data Preparation
The foundation of any machine learning project lies in data preparation. For this project, we used a synthetic dataset containing time series data of product sales across various locations, focusing on attributes such as product code, location code, timestamp, unit sales, and promotional information. When preparing your CSV file for input into a SageMaker AutoML time series forecasting model, ensure that it includes essential columns like item identifier, target, and timestamp.
Ensuring Timestamp Integrity
The first step involves converting the timestamp column to a datetime format for chronological sorting and accurate operations.
Sorting the Data
The sorted dataset is crucial for time series forecasting, ensuring that data is processed in the correct temporal order.
Splitting into Training and Test Sets
The splitting process ensures that the model is trained on historical data while excluding recent data to simulate realistic forecasting scenarios.
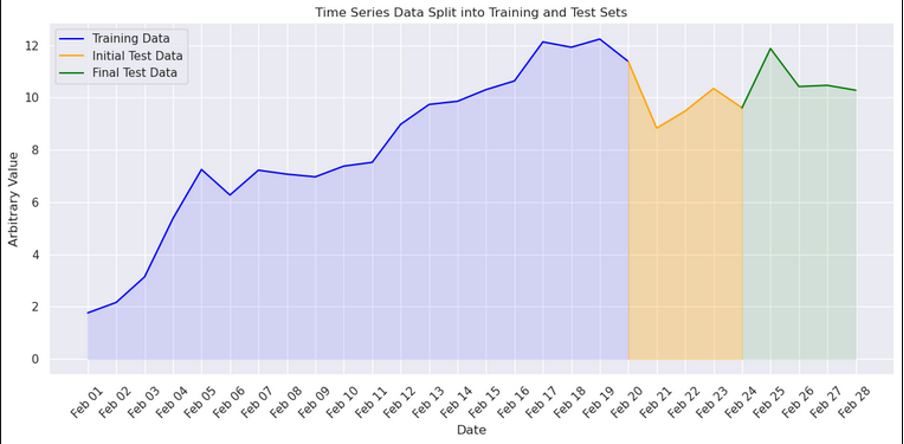
The test dataset is used to evaluate model performance and compute metrics like mean absolute error and root-mean-squared error.
Creating and Saving the Datasets
After categorizing data into training and test sets, aggregating them into comprehensive DataFrames saves the datasets for model training and evaluation.
2. Training a Model with AutoMLV2
SageMaker AutoMLV2 streamlines the process of training, tuning, and deploying machine learning models, providing tailored high-quality models for specific problem types like time series forecasting. Configuring the time series forecasting model involves specifying parameters that utilize historical sales data to predict future sales.
Step 1: Define the Time Series Forecasting Configuration
The configuration includes details like forecast frequency, forecast horizon, quantiles, filling strategies, item identifier, target attribute, and timestamp attribute to optimize the model for accurate forecasting.
Step 2: Initialize the AutoMLV2 Job
Initialization involves defining the problem configuration, AWS role, session, job name, and output path for storing model artifacts.
Step 3: Fit the Model
The fit method starts the training process by preprocessing data, selecting algorithms, training models, and tuning them to find the best solution.
3. Deploying a Model with AutoMLV2
Step 1: Identify the Best Model and Extract Name
Identify the best performing model using the best_candidate method and create a SageMaker model from the best candidate.
Step 2: Create a SageMaker Model
Create a SageMaker model container for serving predictions, specifying the model name and candidate.
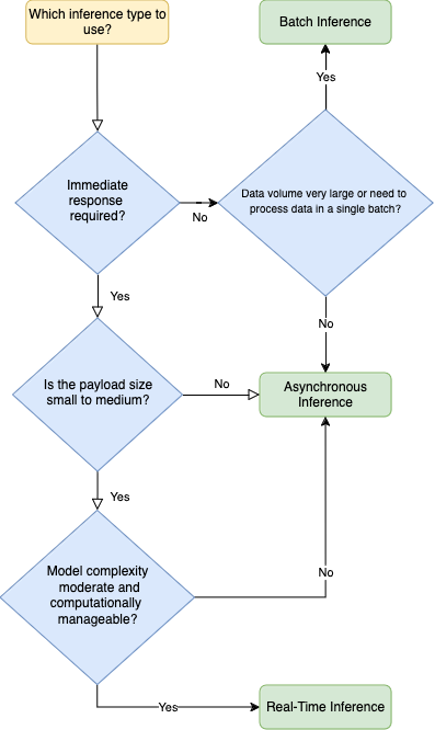
4. Inference: Batch, Real-Time, and Asynchronous
The blog explores batch inference for bulk forecasts and real-time inference for on-demand predictions, highlighting the decision tree for selecting the appropriate endpoint.
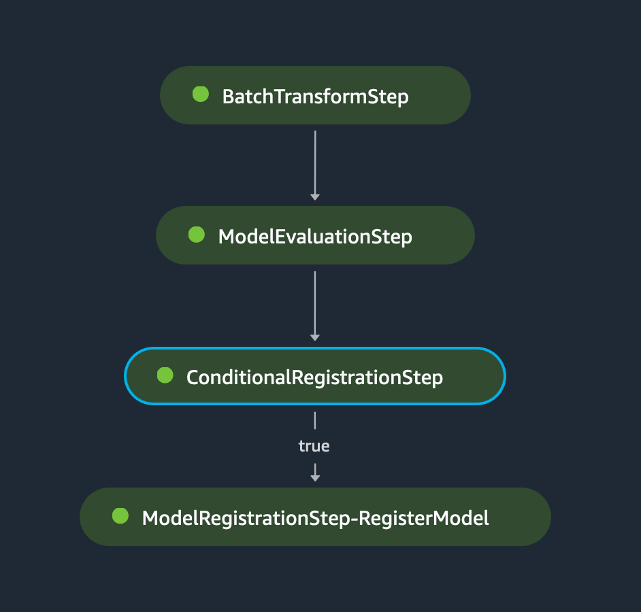
Batch Inference using SageMaker Pipelines
The blog details a comprehensive batch inference pipeline, including transformation steps, evaluation, and conditional model registration for efficient model deployment.
Inferencing with Amazon SageMaker Endpoint in (Near) Real-Time
The blog covers real-time and asynchronous inference methods, suitable for different use cases based on the need for immediate responses versus scalable scheduling of inference requests.
Clean Up
To avoid unnecessary charges, instructions for deleting SageMaker endpoints, pipelines, S3 artifacts, and additional resources are provided.
Conclusion
The post showcases the effectiveness of Amazon SageMaker AutoMLV2 for time series forecasting, demonstrating a robust methodology for predicting future values. By leveraging automation and advanced machine learning capabilities, businesses can make data-driven decisions confidently and efficiently.
If you’re interested in exploring time series forecasting further, consider utilizing the SageMaker Canvas UI for simplified model building and deployment. Visit the SageMaker Canvas page to learn more about its capabilities and enhance your forecasting projects with intuitive machine learning solutions.
About the Authors
Nick McCarthy is a Senior Machine Learning Engineer at AWS, with a background in Astrophysics and Machine Learning. He enjoys traveling, trying new cuisines, and exploring science and technology.
Davide Gallitelli is a Senior Specialist Solutions Architect for AI/ML in the EMEA region, passionate about coding since childhood and AI/ML since university days.