


Harnessing the Collective Intelligence
In a World of Complex Data, Random Forests Stand Tall
Imagine a future where machines make decisions with the wisdom of a thousand experts, each weighing in to deliver the most accurate outcome. It sounds like something out of a sci-fi movie, right? Yet, this is exactly what happens with Random Forest algorithms—a powerful ensemble technique in machine learning that is revolutionizing data-driven decisions.
The Big Idea: Random Forests
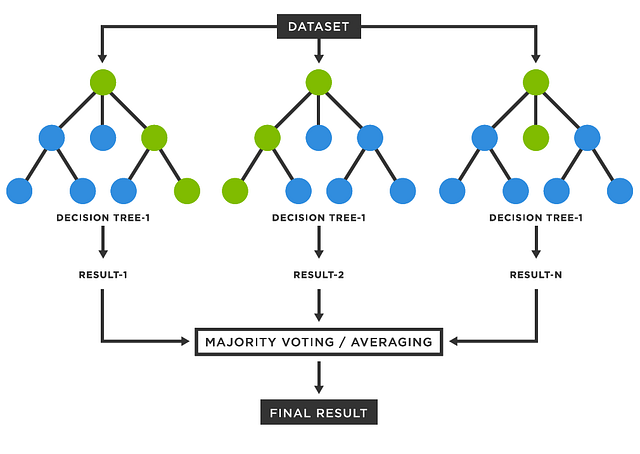
Random Forests is a robust and versatile machine learning algorithm capable of performing both classification and regression tasks. It operates by building multiple decision trees during training and outputting the mode of the classes (classification) or mean prediction (regression) of the individual trees.
But what makes it so effective? The key lies in its ability to overcome the limitations of individual decision trees. While a single decision tree can be prone to overfitting—focusing too much on the specific details of the training data—Random Forest mitigates this by averaging the results of many trees, each trained on slightly different data.
How Does This Work?
Random Forests work by creating an ensemble of decision trees, each trained on a random subset of the data (both samples and features). This randomness ensures that the trees are less correlated, which improves the model’s overall accuracy and robustness. The final prediction is made by aggregating the predictions of all the trees—either by majority vote (in classification) or averaging (in regression).
Here’s a step-by-step breakdown of how a Random Forest model is built:
Data Sampling: For each tree in the forest, a random sample of the data (with replacement) is chosen. This process is known as bootstrapping.
Feature Selection: When building each tree, a random subset of features is selected at each split. This helps in reducing correlation between trees and enhances generalization.
Tree Construction: Each decision tree is grown using the selected data and features. Trees in a Random Forest are usually grown to their maximum depth without pruning.
Aggregation: Once all trees are built, the Random Forest model aggregates their results to make the final prediction. For classification tasks, it uses majority voting, while for regression, it takes the average of the predictions.
Why Use Random Forests?
The Random Forest algorithm offers several advantages that make it a go-to choice in the industry:
- High Accuracy: By combining the results of multiple trees, Random Forests generally achieve higher accuracy than single decision trees.
- Resilience to Overfitting: The randomness in data and feature selection makes the model less likely to overfit, particularly with large datasets.
- Versatility: Random Forests can be used for both classification and regression tasks, and they handle missing values well.
- Feature Importance: The algorithm provides estimates of which features are most important in the prediction, which can be useful for feature selection.
But There Are Challenges Too:
Complexity: Random Forests can be complex to interpret, especially when dealing with large forests with many trees.
Resource Intensive: Training a Random Forest can be computationally expensive, especially as the number of trees increases.
Longer Prediction Times: Due to the ensemble nature, making predictions can take longer compared to simpler models.
Use Case: Predicting Diabetes with Random Forest
Let’s walk through a practical example of using Random Forests to predict whether a patient has diabetes based on various health indicators.
Example: Step-by-Step Implementation
Step 1: Import Libraries and Load the Data
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
import seaborn as sns
import matplotlib.pyplot as plt
# Load dataset (Pima Indians Diabetes dataset)
url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv"
column_names = ['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DiabetesPedigreeFunction', 'Age', 'Outcome']
data = pd.read_csv(url, names=column_names)
Step 2: Data Preparation
X = data.iloc[:, :-1] # All columns except the last one
y = data.iloc[:, -1] # The last column (Outcome)
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.3, random_state=42)
Step 3: Train the Random Forest Model
# Create and train the Random Forest model
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
Step 4: Make Predictions and Evaluate the Model
# Make predictions on the test set
y_pred = model.predict(X_test)
# Evaluate the model
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
class_report = classification_report(y_test, y_pred)
# Display results
print("Accuracy:", accuracy)
print("Confusion Matrix:\n", conf_matrix)
print("Classification Report:\n", class_report)
Step 5: Visualize the Confusion Matrix
# Visualize the Confusion Matrix
plt.figure(figsize=(8, 6))
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues')
plt.title('Confusion Matrix')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.show()
Interpreting the Results
Accuracy: The model achieved an accuracy score, indicating how well the Random Forest classified diabetic and non-diabetic patients.
Confusion Matrix: The confusion matrix shows the number of true positive, true negative, false positive, and false negative predictions, providing insight into the model’s strengths and weaknesses.
Classification Report: This report includes precision, recall, and F1-score for each class, offering a more detailed understanding of the model’s performance.
Conclusion
The Random Forest algorithm stands as a testament to how far machine learning has come. By harnessing the power of multiple decision trees, it offers high accuracy, resilience to overfitting, and valuable insights into feature importance. As we continue to generate and analyze more data, tools like Random Forests will become increasingly vital in turning that data into actionable insights.
Whether you’re navigating complex datasets or simply looking to improve your predictive models, Random Forest is a technique that belongs in every data scientist’s toolkit. The future of decision-making is here, and it’s rooted deep in the forest of machine learning.
References:
Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning: Data Mining, Inference, and Prediction. Springer. A comprehensive book that covers a wide range of machine learning algorithms, including Random Forests, and their applications.
Scikit-learn Documentation. “Random Forest Classifier.” Available at scikit-learn.org. The official documentation for the Random Forest classifier in Python’s scikit-learn library, including examples and parameters.
If you enjoyed this, follow me to never miss another article on data science guides, tricks and tips, life lessons, and more! Follow me on Linkedin for regular updates.
Also Checkout:
- Kanwar Kelide
- Dev Ashish
- Codeclowns