


Enhancing Reliability in LLM-generated Responses
Today, unchecked hallucination poses a significant challenge in Retrieval-Augmented Generation applications. To address this issue, a study was conducted evaluating popular hallucination detection methods across four public RAG datasets. Using AUROC and precision/recall metrics, the study assessed the effectiveness of methods like G-eval, Ragas, and the Trustworthy Language Model in automatically detecting incorrect LLM responses.
As a Machine Learning Engineer at Cleanlab, I have contributed to the development of the Trustworthy Language Model discussed in this article. The study compares methods for detecting hallucinations in RAG systems, aiming to improve response accuracy and user trust.
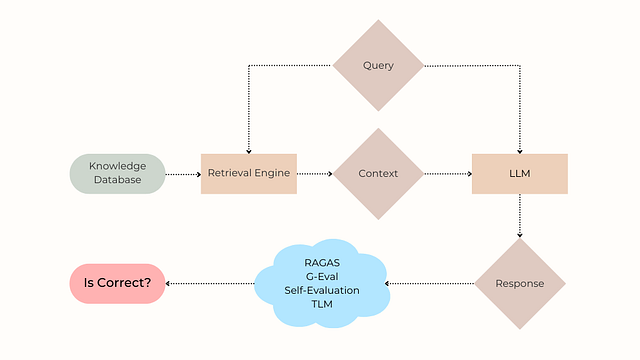
Large Language Models (LLMs) often generate incorrect responses due to hallucination when questions fall outside their training data. Organizations leverage Retrieval-Augmented Generation (RAG) systems to mitigate these errors by incorporating a knowledge base for context retrieval. However, hallucinations and logical errors remain a pressing issue in such systems.
To understand this challenge, it’s essential to examine how RAG systems function. When a user poses a question, the system retrieves relevant context from a knowledge base, which is then inputted into an LLM to generate a response. Challenges arise when the LLM fails to synthesize an accurate answer due to limitations in reasoning abilities or incomplete context.
The study focuses on methods to detect hallucinations arising from LLM-generated responses, which are crucial for ensuring the accuracy and trustworthiness of RAG systems. These detectors play a vital role in high-stakes applications like medicine, law, and finance, alerting users to incorrect responses and prompting further investigation when needed.
Hallucination Detection Methods:
- Self-evaluation (“Self-eval”): A simple technique where the LLM rates its confidence in the generated answer using a Likert scale.
- G-Eval: Automatically develops criteria for assessing response quality based on factual correctness.
- Hallucination Metric: Estimates the degree of hallucination based on the response’s agreement with the context.
- RAGAS: Provides scores like Faithfulness, Answer Relevancy, and Context Utilization to detect hallucinations.
- Trustworthy Language Model (TLM): Utilizes self-reflection and probabilistic measures to evaluate response trustworthiness.
The study evaluates the performance of these methods across four public Context-Question-Answer datasets, analyzing their ability to flag incorrect answers with precision and recall. By utilizing the AUROC metric, the study determines the effectiveness of these detectors in catching errors in RAG systems.
Findings from the benchmarks reveal key insights on the effectiveness of different hallucination detection methods in various RAG applications. TLM, Self-Evaluation, and RAGAS Faithfulness show promise in identifying hallucinations, while other methods like G-Eval and the Hallucination Metric exhibit mixed results.
Combining reliable methods like TLM, RAGAS Faithfulness, and Self-Evaluation can enhance the accuracy and trustworthiness of RAG systems. Future research may explore hybrid approaches and targeted refinements to optimize hallucination detection for specific use cases, ultimately improving response reliability.
Unless otherwise noted, all images are by the author.